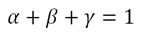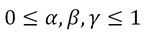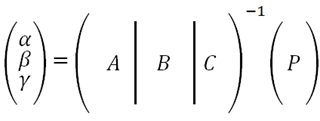I won’t include a meta-programming intro paragraph here, since if you’re not familiar with it – I sincerely hope you stay that way. If you insist, get an idea online or read the book (it’s a good read, but can’t say I recommend it since the entire purpose of this post is to persuade you to not use what it teaches).
I don’t like meta-programming. Passionately so. What’s worse, I seem to be pretty much the only one: I can’t really find any anti-MP texts around! So either
(a) There’s a community of MP-bashers lurking somewhere out of my reach,
(b) I’m waaaay off, and comments to this post would make me see my wrongdoing and shy away to a dark cave for a while,
(c) The world really misses an anti-MP manifest.
However the case turns out it would do me good to try and articulate these thoughts. Here goes.
Meta-Programming is Hacking, not Engineering
One might refer as hacking to pouring orange juice using chopsticks, cutting toothpastes open, or amplifying phones with glass pitchers. On the less-adorable side, we also refer as ‘hacks’ to chewing gum car fixes. Here’s a suggested definition that tries to encompass the creative, improviser, and often lazy aspects of hacking:
Hacking: Achieving a goal by using something in a way it wasn’t designed for.
Defining the other side of the scale is much easier:
Engineering: the discipline, skill, and profession of acquiring and applying scientific … and practical knowledge, in order to design and build … systems and processes.
Now how would you classify meta-programming? It’s inception, for one, gives a clear hint:
Historically TMP is something of an accident; it was discovered during the process of standardizing the C++ language that its template system happens to be Turing-complete, i.e., capable in principle of computing anything that is computable.
C++ types were never designed to perform compile time calculations. The notion of using types to achieve computational goals is very clearly a hack – and moreover, one that was never sought but rather stumbled upon.
The Price
Don’t take it from me, take it from two guys who know an itzy bit more about C++.
Herb Sutter, former secretary of the C++ standardization committee, is one.
Herb: Boost.Lambda, is a marvel of engineering… and it worked very well if … if you spelled it exactly right the first time, and didn’t mind a 4-page error spew that told you almost nothing about what you did wrong if you spelled it a little wrong. …
Charles: talk about giant error messages… you could have templates inside templates, you could have these error messages that make absolutely no sense at all.
Herb: oh, they are baroque.
Jim Radigan, MSVC compiler lead developer, probably understands a thing or two himself.
Jim: We’ve been able to use templates, we’ve been able to do a whole bunch of things.
Charles: Do you use advanced sort of meta-programming at the compiler level?
Jim: We try to steer away from really complex things like that because what happens is.. the tire hits the road when it’s two o’clock in the morning and somebody sends you a pri-zero bug, say, windows doesn’t boot. …
so what we engineered for, clearly, is maintainability. You want somebody to come up to speed, be able to go in, binary search windows and step through the debugger in the compiler and find out where we did the illegal sequence. …
One of the other things that happen when we go to check code into the compiler is we do peer code review. So if you survive that, it’s probably ok, it’s not too complex. But if you try to check in meta-programming constructs with 4-5 different include files and virtual methods that wind up taking you places you can’t see unless you’re in a debugger – no one is going to let you check that in.
… We do use STL, but we don’t go really abstract because we want to be able to quickly debug.
So bottom lines, using meta-programming you end up pouring substantially more effort into writing code that even builds. Your code maintainers end up pouring substantially more effort to be able to understand and debug that code.
The Benefit
Concise, elegant code.
As far as I can say, that is the sole benefit of this ordeal.
Think about that for a second. The very real reward for using MP in your code is the moment of satisfaction of having solved a hard riddle. You did stuff in 100 lines that would have otherwise taken 200. You grinded your way through incomprehensible error messages to get to a point where if you needed to extend the code to a new case, you would know the exact 3-line template function to overload. Your maintainers, of course, would have to invest infinitely more to achieve the same.
I whole heartily empathize – I can get lost for days in such riddles (in and out of programming), and I still remember the joy of having first deciphered a SFINAE construct in code.
It might be a necessary stage in every developers professional path, but one must mature out of it. You have to return and think of your tools as exactly that, tools: unless you’re a standard committee member C++ is a means to an end, not a goal by itself. The geeky pleasure of having mastered the esoteric side effects of some language features is completely understandable, but engineering-wise the price can be formidable – so please, please, fight this temptation valiantly.
Perhaps some day..
The original post title was the way-more-catchy ‘MP is evil’. I modified it to ‘Still Evil’ because I have high hopes: C++11 seems to be very aware of the desire to make compile-time programming a designed language feature, and not just a collection of library hacks.
Let’s talk again in the future. I’ll be very open to revise my opinions when concepts are standardized and any compiler implements constexpr.